


데이터 생산이 폭증하고 있다. 데이터 활용 필요성도 급증하고 있다. 데이터 공급은 넘치고, 데이터 수요도 절실하지만 정작 데이터 소비는 미흡하다. 무엇이 문제일까? 발생하는 데이터를 사용하기 편하도록 쌓아두지 못하기 때문에, 데이터를 활용하려고 할 때 데이터 활용을 위해 가공에 상당한 노력이 들기 때문이다. 이를 해결하기 위한 방안으로 데이터 레이크(Data Lake)를 도입하는 기업이 늘어나고 있다.
데이터 호수와 데이터 늪
데이터 레이크는 데이터가 발생한 형태 대로 보관하는 장소를 의미한다. 데이터에 표준을 적용하여 가공하는 등의 행위를 하지 않는다. 데이터 가공은 데이터를 활용하려고 하는 시점에 수행한다. 대신에 활용 시점에 어떤 데이터 세트가 있는가를 찾기 쉽도록 유일한 식별자를 부여하거나 메타데이터 태그(metadata tag)를 붙여 둔다. 식별자나 태그가 활용 관점으로 부여되지 않으면 데이터 늪(Data Swamp)이 되어버릴 수도 있다.

[그림 1] 데이터 호수와 데이터 늪
데이터 레이크와 데이터 웨어하우스
종래에는 데이터 분석에 활용되는 데이터는 구조적 데이터(Structured Data)였다. 구조적 데이터를 보관하는 장소는 데이터 웨어하우스(Data Warehouse)이다. 데이터 레이크는 데이터 웨어하우스와는 다르다. 데이터 웨어하우스는 구조적 데이터(Structured Data) 만을 관리한다면, 데이터 레이크는 비구조적 데이터(Unstructured Data)를 보관하여 활용할 수 있도록 한다.
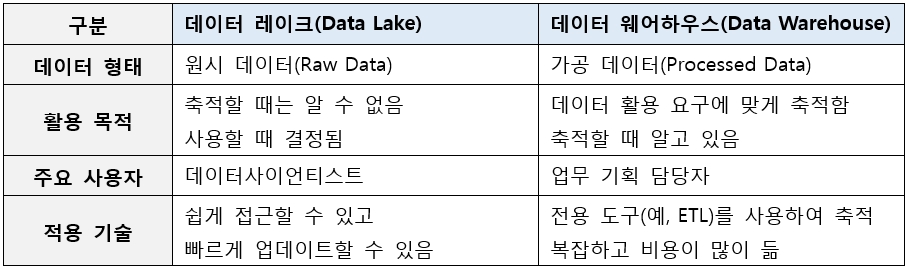
[표 1] 데이터 레이크와 데이터 웨어하우스
데이터 레이크 아키텍처
데이터 레이크는 데이터를 수집하여 정제하고 데이터 의미와 위치 등을 관리하여, 데이터 분석 및 활용을 지원하는 역할을 수행한다.

[그림 2] 데이터 레이크 구조
Data Loading
다양한 소스로부터 데이터를 가져오는 기능을 수행한다. 데이터 소스는 내부뿐만 아니라 외부도 포함한다. 내부 데이터는 OLTP에서 생성되는 거래 데이터와 로그 데이터, 문서 등을 포함한다. 내부 데이터는 스트리밍 데이터 수집, 거래 데이터 연동, 배치 전송 등의 방법으로 수집한다. 외부 데이터는 소셜 데이터, 오픈 데이터, 웹 데이터 등을 크롤링, 스크래핑, 오픈API 등 다양한 방법으로 수집한다.
Raw Data
데이터 로딩의 결과로 확보한 데이터를 가공하지 않고 원시 형태로 쌓아두는 데이터 저장소이다. 데이터 소비자가 Raw Data를 직접 사용하는 경우는 드물다. Raw Data를 활용하기 위해서는 데이터 준비(Data Preparation) 과정을 거쳐야한다. Raw Data 영역은 대량의 데이터를 효율적으로 관리하는 기능이 중요하다.
Data Refinery
데이터를 활용하기 위한 형태로 정제하는 기능을 수행한다. 데이터 전처리(Data Preprocessing)이라고도 한다. 현실 세계에 수집하는 데이터는 완전한 형태가 아니다. 빠져 있는 항목이 있을 수도 있고, 코드 값의 범주를 벗어나는 데이터가 있을 수도 있다. 또는 수집 과정에서 사람의 실수로 잘못된 데이터가 기록될 수도 있다. 데이터 정제는 결측 데이터(missing data), 오류 데이터(noisy data), 일관성 결여 데이터(inconsistent data) 등을 찾아내서 정비한다.
Data Governance
데이터 레이크 내에 저장되어 있는 데이터를 사용자가 쉽게 검색하여 분석에 활용 할 수 있도록 데이터에 대한 정보를 관리하는 영역이다. 데이터가 적재되면 어떤 데이터가 어디에 저장되어 있는지 관련 정보들은 카탈로그에 등록한다. 카탈로그는 데이터 사용자가 필요한 데이터를 쉽게 찾을 수 있도록 한다. 데이터의 의미는 메타데이터로 관리한다. 개인 데이터 보호 규정 준수를 위한 비실명화, 암호화 등의 요건 준수를 위한 통제 기능도 필요하다.
Discovery Sandbox
데이터를 분석할 수 있는 기능을 제공한다. 데이터 탐색(Discovery), 데이터 랭글링(Wrangling), 탐색적 분석(Exploratory Analytics) 등을 지원한다. 데이터 랭글링은 데이터 먼징(Data Munging), 데이터 프랩(Data Prep, Data Preparation의 약칭) 등으로 불리기도 한다. 이는 특정 분석 목적에 사용할 수 있도록 데이터를 변환하는 과정을 의미한다. 데이터 파싱, 필터링 등의 기법을 사용하며 새로운 파생 항목을 만들어내기도 한다.
-끝-
