

본 편에서 컴퓨터가 사진 이미지 속 문자를 읽어내는 원리와 전 편에서 소개한 OCR 오픈소스 (OpenCV, EAST, Tesseract)를 활용한 파이썬 기반 OCR 모델을 만드는 방법을 설명한다.
내츄럴 이미지의 OCR이 어려운 이유
OCR은 일반적인 컴퓨터 비전 기술과 달리 인식대상을 문자로 한정하기 때문에 인식률이 당연히 좋을 것이고, 기술 자체도 단순할 것으로 오해할 수 있다. 하지만 대상 이미지의 다수가 유사한 특성(사이즈, 해상도 등)을 가지고 있으며, 인식할 텍스트의 위치가 규칙적인 경우 등 인식 조건이 특정된 경우에는 맞지만, 현실은 다르다.

[그림 1] 내츄럴 이미지 예시
문서 이미지가 아닌 내츄럴 이미지를 OCR 하는 것은 결코 단순한 기술이 아니다. 내츄럴 이미지 인식이 어려운 이유는 내츄럴 이미지가 갖는 다음과 같은 특성 때문이다.

[표 1] 내츄럴 이미지가 갖고 있는 특성
내츄럴 이미지의 OCR 방법
내츄럴 이미지를 OCR 하기 위해서는 어떻게 해야 할까? 문서 이미지 OCR과의 차이점을 비교하며 1. 이미지 전처리(Image Pre-processing) 2. 대상 검출(Object Detection) 3. 문자 인식(Word Recognition) 등 주요 3단계로 나누어 알아본다.
1. 이미지 전처리: 고도화된 이미지 전처리 단계
내츄럴 이미지의 다양한 상태는 매우 다양하므로 컴퓨터가 이미지를 쉽게 인식할 수 있게 여백 제거, 레이아웃, 밝기, 대비, 해상도 등을 조정하는 이미지 정제작업이다. 이를 ‘이미지 전처리’ 또는 ‘이미지 처리’라고 한다. 문서 이미지는 레이아웃 및 대비 조정만으로 대부분 처리되지만 내츄럴 이미지는 상황마다 다른 다양하고 복잡한 방법의 이미지 전처리가 시도된다.
이미지 전처리의 목적 중 하나는 컨투어스(Contours)를 찾아내는 것이다. 컨투어스란 이미지의 연속된 점과 색깔을 분석한 등고선 형태의 경계그룹으로, 간단하게 사물의 경계선으로 이해할 수 있다. 컨투어스 추출을 통해 박스 형태의 경계선을 찾고 문자가 있을 만한 박스 만을 대상으로 인식 범위를 좁히는 방법을 시도할 수 있다.

[그림 2] 내츄럴 이미지 속 컨투어스
2. 대상 검출: 다양한 형태로 있는 텍스트의 위치파악
내츄럴 이미지 OCR의 가장 핵심적인 부분으로 사진마다 불규칙적인 인식 대상의 위치를 새롭게 찾기 위해 복잡한 알고리즘이 적용된다. 인식할 대상인 관심 영역(ROI, Region of Interest)을 파악한 다음에야 그 글자가 무엇인지 알아볼 수 있기 때문에 이 단계는 검출 성공률을 높여야 하는 중요한 단계다.
텍스트 검출의 프로세스는 텍스트 위치 파악(Text Localization), 텍스트 세그먼테이션(Text Segmentation) 등 두 단계로 나눠 부르기도 한다. 세그먼테이션이란 글자 뭉치를 하나하나 나누는 것을 말한다.
검출률을 높이기 위한 방법으로 이미지 데이터 셋이 어느 정도 공통적인 특징이 있다면 그것에 맞춰 알고리즘을 튜닝하는 것이 가능하다. 차량의 계기판 인식을 한다고 가정했을 때, 계기판의 주행거리는 보통 사진상 네모난 창에 있으므로 이 특징을 살려 알고리즘에 조건을 설정할 수 있다.
3. 문자 인식: 다양한 폰트를 인식할 수 있는 문자인식
내츄럴 이미지는 글자가 어떻게 나타날지 모른다. 글자가 가려질 수도 있고 휘어져 있을 수도 있으며 글꼴 모양 역시 다양하다. 문자인식 부분에서도 문자 위치 검출처럼 이미지 데이터 셋의 공통적인 특징을 이용해 인식 성공률을 높이는 방법이 있다.
그것은 매우 특정한 글꼴을 포함하는 경우이다. 특정 글꼴의 예는 신용카드 번호, 수표 하단에 있는 계좌번호, 그래픽 디자인에 사용되는 양식화된 텍스트가 있다.

[그림 3] 디지털 숫자를 나타내는 모든 경우의 수
세그먼테이션을 통해 글자를 하나하나 잘 쪼겠다면 일반적인 OCR 인식을 사용하는 것보다 디지털 숫자에 최적화된 알고리즘을 적용하는 것이 더욱 효과적일 수 있다.

[그림 4] 7개 영역에 초록색 박스를 두면서 흰 영역과 겹치는 비율을 계산하여 3을 인식함
필체 인식의 경우, MNIST 데이터에 CNN 등의 딥러닝을 이용하여 만든 98%에 달하는 알고리즘과 같은 높은 인식률을 가진 상당수의 알고리즘이 존재한다. 위의 두 사례처럼 특정 문자에 대한 인식 모델을 병행하여 사용하는 것은 좋은 결과를 가져올 수 있다.

[그림 5] Mnist 이미지데이터 예제
텍스트 검출 모델 작성 사례
EAST 모델을 활용하여 텍스트의 위치를 찾고 Tesseract를 이용하여 글자를 읽는 OCR 코드가 어떻게 구성되는지 알아본다.

[그림 6] OpenCV Tesseract OCR 모델 파이프라인
1. 패키지 및 초기 세팅
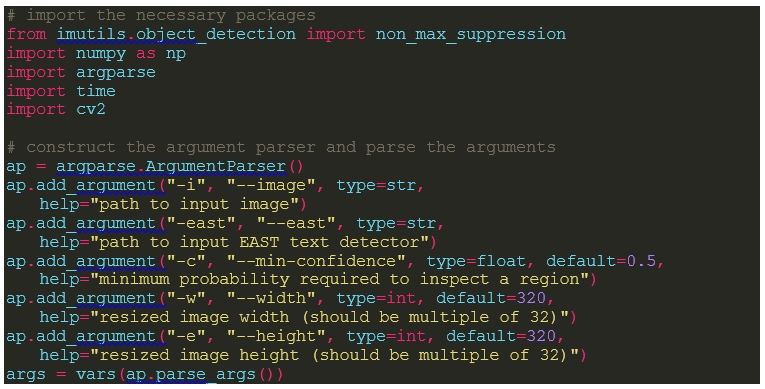
1) 필요한 패키지들을 호출한다. 이 중 argparse란 Terminal(CMD)에서 인수 값을 받아 사용할 수 있게 하는 패키지다.
2) ap에 파서를 생성하여 다음과 같은 인자 값을 추가한다.
- image : 입력 이미지 경로
- east : 텍스트 탐지 모델(사전에 만들어진 모델 호출)경로
- m- in-confidence : 텍스트인지 결정하는 확률 임계 값(Threshold)(기본값 = 0.5)
- width : 크기 조정된 이미지 너비(기본값 = 320, 임의의 32의 배수 사용 가능)
- height : 크기 조정된 이미지 높이(기본값 = 320, 임의의 32의 배수 사용 가능)
사용법은 엑셀의 함수 사용과 유사하며 CMD에서 해당 소스코드의 위치로 이동한 뒤 아래 명령어를 입력하면 된다.
python text_detection.py --image images/lebron_james.jpg --east frozen_east_text_detection.pb
2. 이미지 로드 및 사이즈 조정

1) image 변수에 이미지를 로드하고 orig에 복사한 뒤, H,W에 각각 높이와 넓이를 저장한다.
2) 입력받은(기본값 = 320) 너비와 높이를 newW, newH에 할당한 뒤, 기존 이미지와의 비율을 rW, rH에 할당한다.
3) 입력받은 값으로 이미지 크기를 조정한다.
4) EAST 모델 안에서 우리가 사용할 두 가지 출력 레이어를 호출한다. 첫 번째 층은 시그모이드 활성함수로써, 텍스트를 포함하고 있는지 아닌지에 대한 확률을 나타낸다. 두 번째 층은 피쳐맵 출력으로써 이미지의 기하학적 구조를 나타내며 이를 통해 이미지에 텍스트 박스를 그릴 수 있다.
3. 이미지 전처리 및 EAST 실행
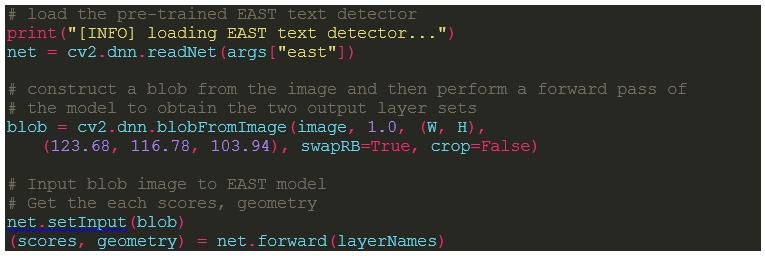
1) cv2를 사용하여 EAST의 신경망 구조를 호출한다.
2) blobFromImage을 통해 이미지 전처리를 한다.
3) 전처리된 이미지를 EAST에 넣어 실행한다.
4) scores와 geometry에 생성된 값들을 저장한다.
4. 피쳐맵 생성
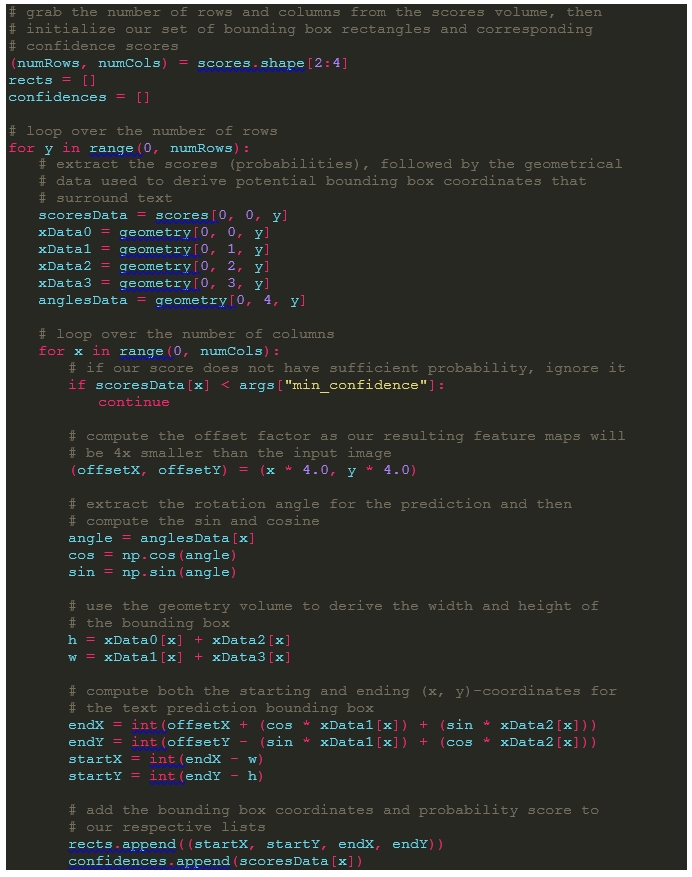
1) scores의 행과 열의 수를 numRows, numCols 두 개의 리스트에 초기화한다.
2) rect에는 텍스트가 있는 부분에 박스 좌표를 저장한다. confidence에는 각 텍스트 박스가 텍스트를 가지고 있을지에 대한 확률을 저장한다.
3) 이중 반복문을 돌면서 박스의 확률이 앞서 설정한 임계 값을 넘을 경우 x,y에 4를 곱하여 저장한다. (EAST를 통과하면 이미지가 자동으로 4분의 1이 되기 때문에 좌표를 원본 이미지와 동일하게 만들기 위함)
4) 각도를 계산한다.
5) 경계 박스영역의 좌표를 구한 뒤 할당한다.
5. NMS 적용
NMS란 대상 검출에서 인접한 대상에서 중복 검출을 피하고 연산량을 줄이기 위하여 사용하는 기법으로 주변의 픽셀과 비교했을 때 확률상 가장 높은 것을 그대로 두고 낮은 것을 제거하는 방법을 말한다.
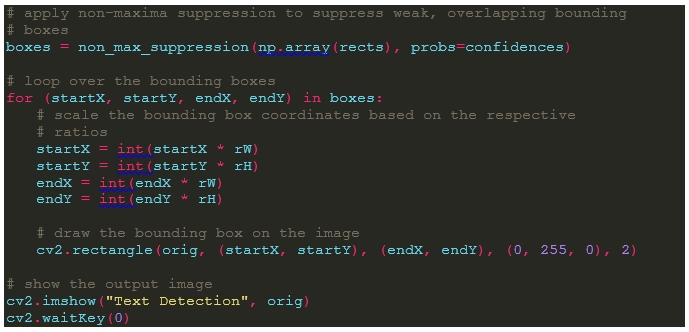
1) Boxes에 rects 리스트에 NMS를 적용하여 유사 영역의 중복된 박스들을 할당한다.
2) 반복문을 통하여 각 텍스트 박스 영역을 그려낸다.
3) 이미지를 출력한다.
6. 결과

위의 코드로 149개의 계기판 이미지 테스트 결과, 텍스트 위치 검출률은 약 51%, 문자 인식률은 10% 미만으로 나왔다. 평가 기준은 검출률의 경우, 추출한 박스 중 주행거리가 포함되면 성공한 것으로 하였고 인식률의 경우, 인식한 텍스트와 해당 주행거리가 완전히 일치할 때 성공한 것으로 하였다. 이는 초기 실험의 결과로서, 앞으로 더 많은 데이터를 대상으로 실험을 반복하면 원하는 수준의 성능을 달성할 것으로 예상된다.
- 끝 -
<참고자료>
1. https://www.pyimagesearch.com/2018/
