


살아가는 것은 선택의 연속이다. 점심으로 어떤 메뉴를 고를까? 어느 회사의 제품을 살까? 새로 가입할 적금은 어디에 들까? 선택하는 방식은 사람 성향에 따라 다르다. 위험이 따르더라도 최대 만족을 추구하는 유형도 있고 선택에 따른 후회 최소화를 중요하게 생각하는 유형도 있다.
기업의 매출이 발생하는 것은 개인으로부터 선택을 받아야 가능하다. 기업이 개인에게 자신의 제품이나 서비스를 제시할 수 있는 기회는 많지 않다, 고객과 마주친 순간에, 기업이 제시하는 오퍼링의 수는 제한적이다. 고객은 짧은 시간에 기업이 제안한 내용을 살펴보고 선택 여부를 결정한다.
기업으로서는 고객이 좋아할만한 오퍼링을 제시하는 것이 중요하다. 이를 위해서 사용하는 것이 추천모델이다. 추천모델의 성능은 고객의 구매 의사결정에 영향을 미친다. 디지털 시대는 추천모델의 중요성은 더욱 커진다. 언택트 환경에서 고객 응대를 해야 하기 때문이다. 과거에는 수완이 좋은 영업 사원이 고객과 대화하면서 고객이 원하는 추천을 할 수 있었다. 지금은 디지털 환경에서 고객 데이터를 기반으로 고객이 원하는 추천을 해야 한다. 추천모델의 여섯 가지 유형을 알아보고, 이를 구축하기 위한 추천 참조 모형을 정의해본다.
추천모델은 특정 사용자가 선호하는 제품이나 서비스를 예측해내는 일을 한다. 여기에는 수학 모델과 알고리즘이 사용된다. 초기의 추천은 주로 참조모델(reference model)을 사용했다. 참조모델 기반 추천은 개인의 성향을 직접적으로 분석하지 않는다. 보다 정확한 추천을 위해서는 개인의 특성과 상황을 고려한 추천을 해야 한다. 이를 개인 맞춤 추천이라고 한다. 통상적으로 사용되는 추천모델은 하나의 방식만이 아니라 알려진 알고리즘을 다양하게 복합적으로 적용하는 하이브리드 모델이다. 추천에 인공지능이 적용되면 대규모 케이스를 머신러닝으로 분석하여 추천 모델을 만들어내고 모델이 산정하는 점수를 기반으로 추천하게 된다.
![[그림 1] 추천모델 패턴](/news/photo/202011/300979_3545_5151.jpg)
1. 사용자 기반 협업 필터링

유사 성향의 타인이 구매한 제품을 추천하는 방식이다.
구매이력 및 평가결과를 기반으로 유사한 선호도를 가진 사용자 도출→구매하지 않은 제품 중 유사 선호도 사용자의 평가결과를 기반으로 추천 순으로 처리한다.
전제 : 유사한 취향을 지닌 A의 과거 구매 아이템은 미래에도 유사한 항목을 좋아할 것이므로 B에도 해당
활용 : 의류, 마트상품 등 추천
장점 :
• 제품 정보, 사용자 정보 불필요하므로, 구현 용이
• 사용자에게 깜짝 놀랄만한 새로운 아이템 추천 가능
단점 :
• 유사도 계산을 위해 모든 사용자, 제품, 평가 정보가 메모리에 로드되기 때문에 계산 비용 높음
• 정보가 없는 첫사용자 추천 불가(콜드 스타트 문제)
• 사용자 평가정보가 거의 없는 경우 성능 저하
• 사용자 또는 제품 자체에 대한 콘텐츠 정보가 없기 떄문에 평가 정보만으로는 정확한 추천 불가
• 개인화 추천 불가
2. 아이템 기반 협업 필터링

사용자가 과거에 구매한 유사 제품을 타인 평가를 기반으로 추천하는 방식이다.
사용자들의 제품 선호도를 기반으로 아이템 유사도 계산→구매하지 않은 제품 중 가장 유사한 제품 추천 순으로 처리한다.
전제 : 사용자가 과거에 아이템 A를 좋아했다면, 타인이 A와 유사하다 평한 B 아이템도 좋아할 것
활용 : 영화, 음악 등 추천
장점 :
• 제품 정보, 사용자 정보 불필요하므로, 구현 용이
• 사용자에게 깜짝 놀랄만한 새로운 아이템 추천 가능
단점 :
• 유사도 계산을 위해 모든 사용자, 제품, 평가 정보가 메모리에 로드되기 때문에 계산 비용 높음
• 정보가 없는 첫사용자 추천 불가(콜드 스타트 문제)
• 데이터가 거의 없는 경우 성능 저하
• 사용자 또는 제품 자체에 대한 콘텐츠 정보가 없기 떄문에 평가 정보만으로는 정확한 추천 불가
• 개인화 추천 불가
3. 콘텐츠 기반 추천

사용자커뮤니티 정보없이, 사용자의 선호도(구매이력)와 제품 속성정보만으로 유사 상품을 추천하는 방식이다.
제품 속성정보(특징) 생성→사용자 프로필과 제품 속성과 관련된 선호도 생성→추천을 생성하고 좋아할 만한 제품 예측 순으로 처리한다.
전제 : 사용자가 과거에 아이템 A를 좋아했다면, A와 유사한 B 아이템도 좋아할 것
활용 : 영화, 음악 등 추천
장점 :
• 개인화된 추천 가능
• 추천 사항을 처리 또는 생성하기 위해 모든 데이터 로드 불필요→실시간 적용 가능
• 객관적인 제품 속성 기반이므로 협업 필터링 방식 대비 정확도 높음
• 정보가 없는 첫사용자 추천 가능(콜드 스타트 문제 해결)
단점 :
• 사용자의 선호도에만 집중된 편협한 추천
• 선호도와 무관한 신규 제품, 최신 트렌드 파악 불가
4. 상황인식 추천
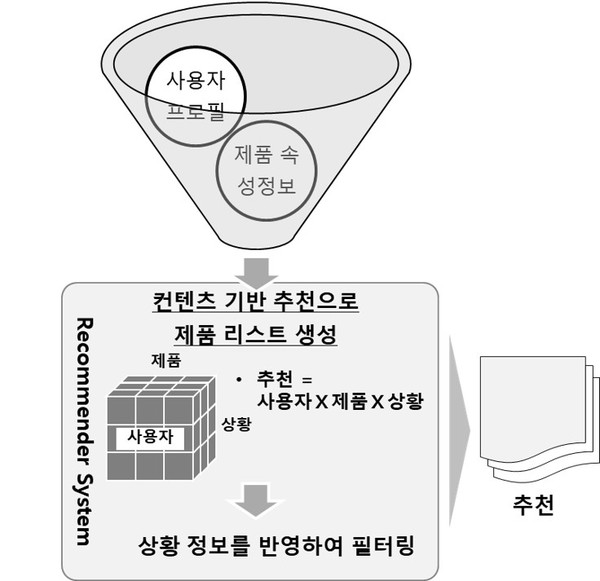
장소, 시간, 날씨, 계정, 기분, 디바이스 등을 고려해 사용자의 상황을 정의하고, 개인화된 추천 사항을 제안하는 방식이다.
콘텐츠 기반 추천 방식을 기반으로 사용자에 대한 제품 추천 리스트 생성→현재 상황에 한정된 추천 사항들 필터링 순으로 처리한다.
유형 :
• 사전 필터링 방식 : 상황정보를 사용자 프로필과 제품 속성정보에 적용
• 사후 필터링 방식 : 사용자 프로필과 제품 속성정보를 바탕으로 개인 추천 리스트 생성후 상황정보 적용
활용 : 의류, 레스토랑, 식료품 등 추천
장점 :
• 사용자의 현재 상황에 맞는 추천을 생성하기 때문에 콘텐츠 기반 추천 시스템보다 진보된 추천
• 실시간 추천
단점 :
• 사용자의 선호도에만 집중된 편협한 추천
• 선호도와 무관한 신규 제품, 최신 트렌드 파악 불가
5. 하이브리드 추천

다양한 추천시스템들을 결합시킴으로써 하나의 시스템이 지닌 단점을 다른 시스템의 장점으로 대체하는 방식이다.
첫번째 추천시스템을 선택하여 적용→적용 방식에 따라 두번째 추천시스템을 선택하여 적용하고 최종 제품 추천 순으로 처리한다.
유형 :
• 가중 방식 : 처음 시작시 추천 기법의 각 결과에 대해 동일 가중치 적용→사용자의 추천 사항 반응을 평가해 가중치 조정
• 혼합 방식 : 추천 기법별로 추천사항 도출 추천사항 혼합하여 전달
• 캐스케이드 방식 : 협업 필터링 이용해서 추천 사항 생성→콘텐츠 기반 추천 기법 적용후 최종 추천
• 특징 조합 방식 : 다양한 추천 기법과 최종 추천 방식의 특징을 조합
활용 : All
장점 :
• 콜드 스타트 문제와 데이터 희소성 문제 해결
• 개별 모델들보다 훨씬 견고하고 확장 가능
• 여러 방식들의 조합으로 정확도 향상
단점 :
• 구현 및 모듈 유지 복잡
6. 모델기반 추천
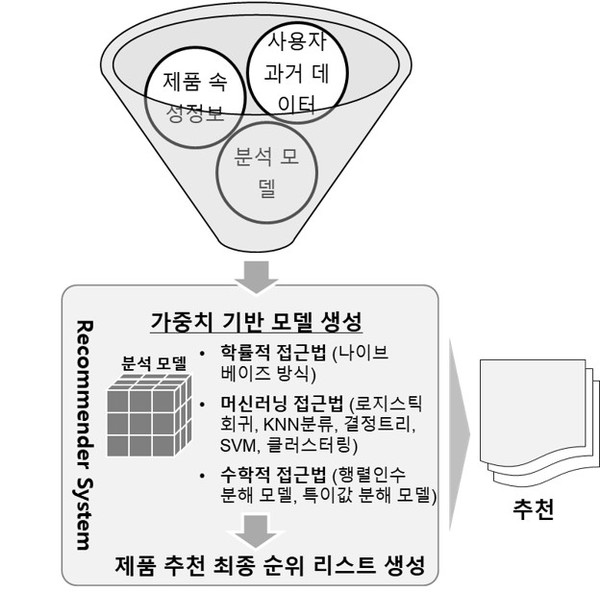
사용 가능한 과거 데이터를 이용해서 자동적으로 학습된 가중치 기반 모델을 생성하고, 가중치를 이용해 제품에 대해 새롭게 예측한 후 특정 순서로 순위가 매겨진 최종 결과를 추천하는 방식이다.
사용자의 과거 데이터를 기반으로 학습된 가중치로 모델 생성→학습된 가중치를 이용하여 제품에 대해 새롭게 예측→특정 순서로 순위가 매겨진 최종 결과를 이용해서 추천 순으로 처리한다.
유형 :
• 확률적 접근법 : 사용 가능한 데이터로부터 사전 확률을 이용해 확률 모델 생성 각 사용자의 제품에 대해 좋고 싫음의 확률을 계산하여 추천 순위리스트 생성
• 머신러닝 접근법 : 과거 사용자와 제품 정보를 이용해서 특징을 추출해 분류한 후 머신러닝 모델 구축 제품 추천 최종 순위 리스트 생성
• 수학적 접근법 : 제품에 대한 사용자의 등급 및 상호작용 정보는 단순한 행렬이라 가정 해당 행렬에 수학적 접근법을 적용해서 등급을 예측
활용 : All
장점 :
• 가중치 자동학습을 통해 관리편의성과 정확성 향상
• 실시간, 개인화 추천 가능
단점 :
• 구현 복잡
넷플릿스는 사용자의 시청기록, 다른 콘텐츠 평가 결과, 유사 취향 사용자의 선호 대상, 장르/카테고리/배우/출시연도 등 콘텐츠 정보, 하루중 시청 시간대, 시청 디바이스, 시청 시간 등을 기반으로 추천한다.
유튜브는 Video Quality(유저에 상관없이 비디오의 절대적인 품질을 측정하는 점수. 비디오의 총 시청 횟수나 rating, 혹은 공유된 횟수 등), User Specificity(유저 활동 로그를 기반으로 개인화된 추천 점수. 후보셋 생성 단계의 Seed Set을 사용해서 추출), Diversification(같은 채널이나 비슷한 비디오가 너무 많이 추천되지 않게 후보 셋을 조정)을 사용하여 랭킹을 부여한다.
기본적으로는 Video quality와 User Specificity로 비디오들의 랭킹 점수를 매겨서 추천 리스트를 생성한 뒤, 생성된 리스트에서 Diversification에 해당하는 콘텐츠를 조정하는 방식을 사용한다.
비즈니스 모델과 제공하는 상품 및 서비스 특징에 따라 다르겠지만, 추천 엔진 및 시스템을 구축한다면, 어떻게 구성해야 할까?
유튜브처럼 사용자 상품평을 기반으로, 혹은 상품/서비스 제공업체의 추천목록을 기반으로, 혹은 사용자들의 상품 구매이력을 기반으로 “상품추천SeedSet”을 만든다.
사용자의 구매 성향을 도출하거나, 추천 상품을 제외하기 위해 “구매” 테이블을 참조하고, 유사 성향의 타인을 참조하기 위해 “사용자유사도”를 도출하며, 동일 관심사항에 해당하는 상품을 선별하기 위해 “상품유사도”를 도출하여 추천리스트를 만들고, 사용자가 구매한 상품은 제외하는 방식이 가장 보편적이지 않을까 생각한다.
![그림 2] 추천엔진을 위한 참조모델 예시](/news/photo/202011/300979_3552_046.jpg)
