

파이썬(Python) 기반 오픈소스 OCR 모델을 만드는 것을 두 편으로 나누어서 설명한다. 첫 편에서 OCR의 개념 및 기업에서의 효용, 그리고 대표적인 OCR 오픈소스를 소개한다. 다음 편에서는 컴퓨터가 사진 이미지 속 문자를 읽어내는 원리와 오픈소스를 활용한 간단한 OCR 모델을 만드는 방법을 설명한다.
OCR은 무엇인가

[그림 1] OCR 기술 원리
OCR(Optical Character Recognition, 광학 문자 인식)은 인쇄물 또는 사진 상의 글자와 이미지를 디지털 데이터로 변환해주는 자동인식기술이다. 기술 사용의 예로 명함의 텍스트나 서류상의 필체 정보 인식 등이 있다. 상용 OCR은 현재까지 20여년간 사용 되었으며, 기술발전으로 인해 문서 이미지만 인식하던 기술에서 일상적인 사진이나 동영상 속 문자까지 인식하는 기술로 발전되고 있다.
OCR의 기술 구분은 인공지능기술 중 ‘컴퓨터 비전 기술’¹에 해당하며 전 세계적으로 활발하게 연구가 이루어지고 있다. OCR 분야는 최근 기계학습 기반의 알고리즘(엔진)을 활용하면서, 인식률이 크게 높아졌다. 딥러닝(CNN 및 RNN 등)을 적용해 정확도가 이전보다 향상되었으며 규격 이미지(스캔문서 이미지 등)에서 OCR 기술 적용 시 약 90%의 정확도를 보인다.
1. 컴퓨터 비전 : 컴퓨터가 이미지 또는 영상을 인식하는 기술로 사물인식, 얼굴인식 등을 수행하여 자율주행 자동차의 주변 인식 또는 명함 인식 모바일 앱 등에 사용된다.
왜 OCR인가
OCR은 기업의 이미지 및 문서처리업무를 자동화하여 프로세스 효율화 및 비용 절감에 효과적이다. 여러 종류의 스캔 서류를 분류하거나 거래 계약서의 주요 내용에 대해 ‘동의함’에 체크가 되어있는지 확인하는 업무 등 전산화되지 않은 종이 문서 업무처리에 OCR을 적용할 수 있다.
또한 모바일 사용이 대중화되면서 스캔 이미지가 점차 모바일 촬영 이미지로 대체되고 있으며 처리량 또한 많아지고 있다. 고객의 각종 서류를 모바일 촬영 이미지로 수집하는 경우, 수집된 이미지는 내부 자료화를 위해 사진 속 문자 내용을 사람이 일일이 엑셀파일 또는 데이터베이스에 입력하는 수작업 대신 OCR 기술을 적용한다면 생산성이 크게 높아질 수 있다.
OCR은 증빙서류 등의 문서 처리가 많은 금융회사에서는 이미 사용하고 있다. 특히 보험사는 고객들이 모바일로 촬영하여 보낸 청구 서류 이미지 인식에 OCR를 적용하여 보험금 청구 후 지급까지의 시간을 단축함으로써 프로세스 효율성을 높이고 있다. 또한 번거롭고 시간이 오래 걸리는 개인정보 입력 단계를 자동화함으로써 고객 편의성도 향상시킬 수 있다.
OCR 오픈 소스
OCR 솔루션을 도입하기 전에 오픈소스 OCR 알고리즘과 벤치마크 테스트를 해보는 것이 바람직하다. OCR의 기능 영역(이미지 전처리, 텍스트 위치 검출, 글자 인식)별로 사용되는 대표적인 오픈소스와 최근 동향에 대해 소개하고자 한다.
[그림 2] Open CV와 Tesseract OCR
이미지 및 영상 처리 부분에서 가장 권위가 있는 오픈소스인 OpenCV는 C 기반으로 작성 되었으며 자바(JAVA), 파이썬(Python) 등의 언어로도 제공된다. OpenCV는 OCR 에서 이미지 전처리²와 텍스트 위치 검출(Text-Localization)에 사용 가능하다.
2. 이미지 전처리 : 컴퓨터가 이미지를 쉽게 인식할 수 있게 이미지를 정제하는 선제 작업이다.
올해 10월 말, OpenCV3 출시 3년 만에 OpenCV4 알파 버전이 발표될 예정이다. 인식 처리 속도와 사물의 경계선을 이해할 수 있는 컨투어스(Contours) 추출 성능이 개선되었으며 현재 비 정식 버전을 사용할 수 있다.
텍스트 위치 검출 부분에서, EAST(An Efficient and Accurate Scene Text Detector)는 17년 4월 공개되었고, OpenCV를 기반으로 딥러닝 파이프라인을 새로운 방식으로 개선함으로써, 높은 검출률을 달성하여 주목받고 있다.
글자 인식 부분의 OCR 오픈소스 전통 강자 Tesseract는 휴렛팩커드(Hewlett Packard)가 1980년대에 개발했으며 2005년 오픈소스로 개방되었다. 구글은 이 프로젝트를 2006년 이후 후원해 왔다. 2018년 현재 딥러닝 학습 기능이 내장되어 있는 강력한 OCR 도구이다. Tesseract는 곧 v4가 배포될 예정이며 LSTM(딥러닝의 일종) 기반으로 개발되어 인식률이 크게 높아졌다.
OpenCV, EAST detector와 함께 Tesseract를 사용하면 훌륭한 조합이 된다. 작년과 올해에 OCR 오픈소스의 새로운 버전이 발표됨에 따라 오픈소스를 사용한 OCR 엔진 및 솔루션 성능이 전반적으로 크게 향상되었다. 그 외, 상당한 수준의 정확도를 보이는 상용 오픈 API도 존재한다. 구글 클라우드 비전(Google Cloud Vision), 마이크로소프트 컴퓨트 비전(Microsoft Computer Vision) 등이 대표적이다.
OCR 컴피티션
여러 OCR 알고리즘의 기술 동향을 파악하고 성능을 비교할 수 있으며 도입할 솔루션의 성능을 이 데이터를 통해 객관적으로 평가할 수 있는 대회가 있다.
국제 컴퓨터 문자인식 대회인 ICDAR 로버스트 리딩 컴피티션(ICDAR Robust Reading Competition)은 국제패턴인식 협회인 IAPR 주관으로 현재 진행 중이다. 전 세계에서 참여하는 이 대회는 컴퓨터 비전 문자인식 연구의 발전과 공정한 경쟁을 목적으로 2003년부터 2017년까지 총 6차례 개최되었다.
이 대회는 몇 가지 세부 종목으로 나뉘는데 다양한 상황을 가정한 일반 이미지 인식, 의학 문서 인식, 실시간 영상인식 등이 있다.
세부 종목별로 평가 기준이 다르지만 공통적인 기준은 텍스트 위치파악(Text-Localization), 문자 인식(Word-Recognition), 전체 처리과정(End-to-End) 등이다. 평가하고자 하는 OCR 모델이 있다면 적절한 데이터 셋을 선택해야 하며 특수목적을 위한 OCR 모델의 평가 데이터 목적으론 적절하지 않을 것이다.
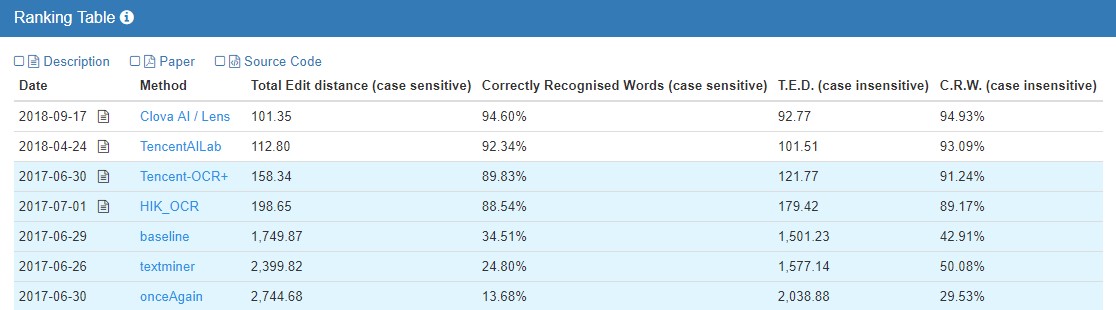
[그림 3] ICDAR2017 DeTEXT Competition – Word Recognition부문 정확도 순위
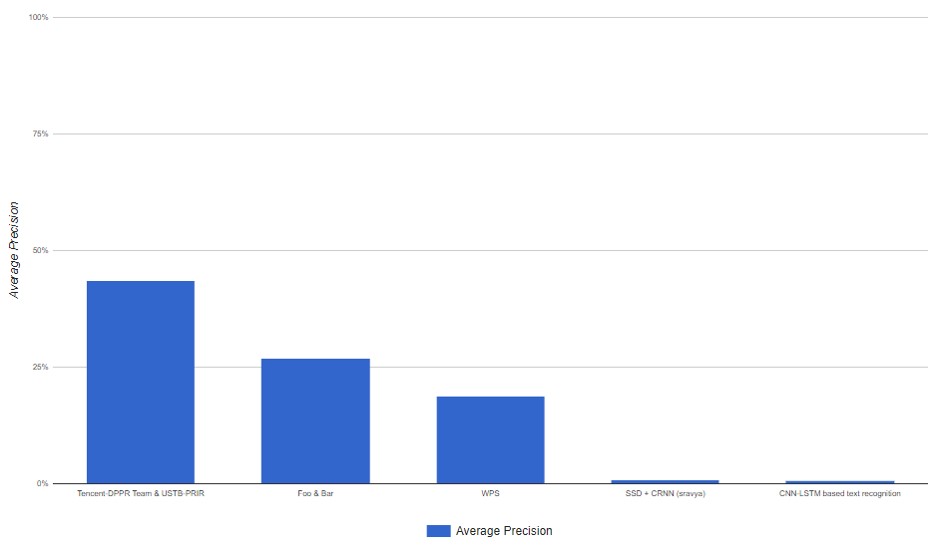
[그림 4] COCO-Text의 End-to-End부문 정확도 그래프
OCR의 미래
현재 기업이 사용하는 OCR은 문서 이미지 위주로 사용되지만, 내츄럴 이미지 또는 영상 분야에서 사용될 경우 활용가치는 더욱 커질 것이다. 예를 들어, 손해보험사에는 주행거리에 따라 보험료를 할인해주는 상품이 있다. 이것이 가능하게 하려면 고객들이 가입 시점의 주행거리 사진과 특정 주기의 사진을 비교하여 할인 대상인지 확인하는 작업이 필요하다.

[그림 5] OCR 기술의 한계점이 드러나는 내츄럴 이미지
실제로 이 업무는 보험사마다 열 명 이상의 직원이 수행하거나 또는 아웃소싱으로 수행되고 있다. 이러한 사진 이미지 처리 업무량의 50%만 자동화 되어도 비용과 시간을 크게 절약할 수 있다. 현재는 사진 별로 계기판 숫자의 위치나 모양, 해상도, 화질 등이 너무나 다양하므로 현재의 OCR 기술로는 한계가 있다.
OCR이 고도화될수록, 내츄럴 이미지 관련 업무에 대해 OCR을 확대 적용함으로써 OCR의 효용성은 더욱 더 증가할 것이다.
또한, OCR은 프로세스의 효율화 및 자동화 측면에서 RPA와 연계했을 때 더욱 효과적으로 사용할 수 있다. RPA는 단순 반복적인 업무 프로세스를 사람 대신 소프트웨어 로봇이 수행하게끔 하는 업무자동화 기술이다. 지금까지는 OCR을 통해서 인식한 값들을 저장 및 전송하는 것에 그쳤다면 RPA와 연계하여 그 다음 처리되는 사람의 업무까지 프로세스 전체를 자동화할 수 있다.
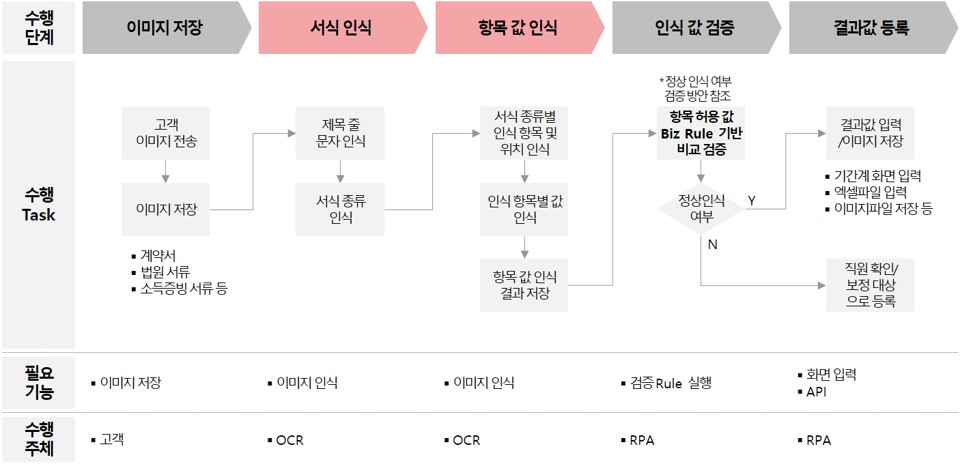
[그림 6] RPA와 연계 시 OCR 적용 방향
자동화 하고자 하는 프로세스 중간에 종이 문서나 사진 처리가 있다면 그 프로세스는 RPA의 대상 업무가 될 수 없거나 단절된 자동화로 반쪽짜리 자동화에 불과하다. 위의 경우, 저장된 이미지를 확인하고 항목 값을 데이터화 하는 부분(빨간색 영역)에 OCR을 적용하면 프로세스의 처음부터 끝까지 완전 자동화를 달성할 수 있다.
- 끝 -
<참고자료>
1. https://github.com/hoya012/deep_learning_object_detection
2. https://opencv.org/opencv-4-0-0-alpha.html
3. https://arxiv.org/abs/1704.03155
4. https://github.com/tesseract-ocr/tesseract
