

1. 데이터 패브릭이란?
기업에서 데이터를 자산화하고, 데이터 활용을 민주화 하기 위해서는 모든 직원이 필요한 데이터에 대해 빠르고 쉽게 접근×활용할 수 있어야 한다.
그러나, 기존의 특정 조직 중심(IT부서, 데이터 및 분석 전담조직)의 데이터 접근×활용×관리 체계에서 벗어나 전사 업무조직으로 데이터에 대한 권한과 도구를 확산한다고 하더라도 여전히 장애물이 존재한다.
빅데이터와 클라우드 시대의 활성화로 점점 더 많은 새로운 데이터가 이기종의 다양한 시스템에 분산 저장되고 있어 데이터에 대한 쉽고 빠른 접근과 활용, 그리고 통합적인 관리가 어려운 환경에 직면하고 있기 때문이다.
‘데이터 패브릭(Data Fabric)’은 이렇게 다양한 이기종 시스템에 분산되어 저장된 데이터에 대한 통합된 접근과 활용을 위한 솔루션으로써 최근 각광받고 있다. 가트너에서도 2022년 이후의 12가지 차세대 전략기술 중 하나로 데이터 패브릭을 지목한 바 있다.
데이터 패브릭에 대해 가트너에서는 “분산된 데이터 환경에서 데이터 공유를 위한 원활한 접근을 가능하게 하는 체계”로 정의하고 있다. 이외에도,
- “데이터세트가 너무 커서 물리적으로 이동할 수 없게 되는 현상을 해결하기 위한 솔루션”(Will Ochandarena, AWS의 수석 상품 매니저)
- “모든 조직의 데이터를 확장 가능한 단일 플랫폼으로 통합하는 포괄적 방법” (MapR)
- “물리적 환경과 가상 환경의 경계를 넘어서는 대규모로 구현된 정보 네트워크" (Fobes)
- "분산된 환경에서 데이터 액세스와 공유를 보다 쉽게 하는 일관된 단일 데이터 관리 프레임워크 디자인”(TechRepublic)
등으로 데이터 패브릭에 대해 다양하게 정의하고 있으며, 종합해보면 “다양한 시스템에 분산된 대규모 데이터에 대한 통합적인 접근과 공유를 위한 정보네트워크 체계”라 할 수 있다.
2. 능동적 메타데이터(Active Meta Data)
가트너에서는 데이터 패브릭을 위한 핵심 3가지 레이어를 데이터 통합, 지식그래프와 능동 메타데이터 분석, 데이터 카탈로그(메타데이터)로 제시했다.
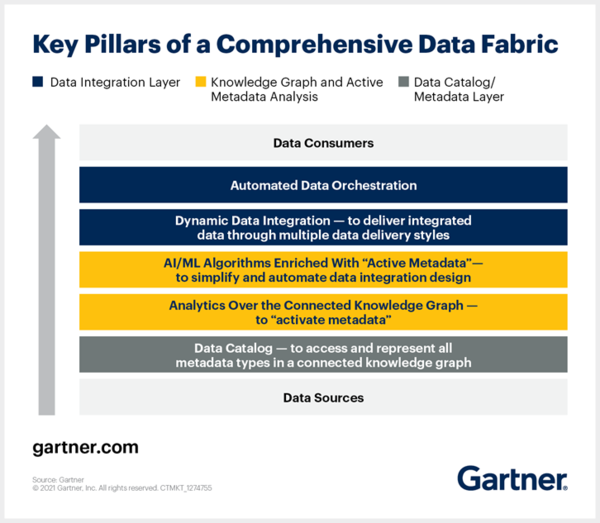
위 그림에서 보는 바와 같이 데이터 패브릭이 제대로 작동되고 지속성을 가지기 위해서는, 다양한 분석기술을 활용하여 분산된 데이터에 대한 지속적이고 지능적인 통합과 제공이 능동적으로 이루어지는 메타데이터 체계 마련이 필수적이다.
기존의 메타데이터 관리는 데이터 선별과 등록이 ‘사람’의 ‘판단’ 의해 ‘간헐적’인 ‘수작업’으로 이루어지는 ‘정적이고 수동적인 방식(Passive Meta Data)’이었다. 그러나 다양한 새로운 데이터가 끊임없이 생성되어 분산된 시스템에 저장되는 현재의 환경에서, 수동적인 메타데이터 관리 방식으로 데이터를 인지×등록하기에는 불가능해지고 있다. 또한 개별 개별의 새로운 데이터를 인지하는 문제 뿐만 아니라, 데이터와 데이터간의 유의미한 관계를 사람이 판단하는 데에도 한계에 봉착해 있다.
이러한 문제점을 해결하기 위해 ‘상시 작동’하면서, ‘지능적으로 생성’하고, ‘처방’으로 이어지는 ‘플랫폼’ 기반의 능동 메타데이터(Active Meta Data) 체계로의 전환이 이루어지고 있다.

즉, 항상 새로운 데이터 발생과 사용을 감시하여 수집하고(상시 작동), 데이터 간의 관계에 대한 지능화 된 파악을 통해 연결하고(지능적 관계 생성), 나아가 최적화 된 데이터 운용 및 데이터 사용현황 기반 시스템 운용을 제안해주고(처방), 데이터에 대한 검색과 협업이 원활이 지원(플랫폼)되는 것이 능동 메타데이터 관리×활용 체계이다.
이러한 능동 메타데이터 체계로 전화하기 위해서는 다음의 기술적 요소가 지원되어야 한다.
1) 메타데이터 레이크(Meta Data Lake)
모든 종류의 메타데이터를 원시 및 추가 처리된 형식으로 저장하는 통합 저장소로, 단순 데이터 저장소로서의 기능 뿐만 아니라 개방형 API를 통해 쉽게 액세스 할 수 있는 기능을 포함해야 한다.
2) 지식 그래프 분석(Knowledge Graph Anaytics)
메타데이터를 개별 개별 등록하는 것에서 나아가, 데이터 간의 관계를 지능화 된 네트워크 분석을 통해 인지하여 생성할 수 있어야 한다.
3) 증강 분석(Augmented Analytics)
규칙 기반 프로그래밍에 의존하지 않고 데이터에서 학습하는 머신러닝과 구조화 되지 않은 데이터를 분석할 수 있는 자연어처리(Natural Language Processing) AI를 통합적으로 활용하는 분석이 필요하다. 이를 통해 데이터에 대한 통찰력 발굴을 자동화하고, 사용자는 자연어로 데이터를 쿼리할 수 있는 환경이 제공되어야 한다.
4) 증강 데이터 관리(Augmented Data Management)
지속적으로 증가하는 데이터 관리 작업 부하를 개선하고 자동화 하기 위한 AI 기술이 적용된 데이터 관리체계가 필요하다.
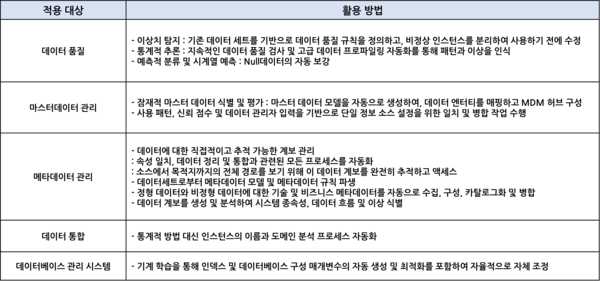
5) 검색엔진, 협업도구
데이터 포탈을 통해 데이터 카탈로그(메타데이터)에 대해 자연어 기반으로 검색(Pull)하고, 사용자에게 데이터 사용량이 많은 인기 데이터나 검색한 데이터와 연관된 데이터를 추천(Push) 하는 검색엔진이 제공되어야 한다.
또한 데이터 관리, 접근 및 활용을 위한 사용자간 협업(토론, 알람, 신청×승인 워크플로우, 크라우드 소싱 등)을 위한 도구가 플랫폼 내에 통합되어 운영되어야 한다.
오늘날 많은 기업들이 데이터 접근과 활용의 문제점을 해소하기 위해 데이터 포탈 시스템을 구축하기 시작했다. 데이터 포탈 구축 시, 기존의 기술(IT) 메타에서 나아가 비즈니스 메타와 운영 메타 정보를 포함하는 확장된 데이터 카탈로그를 고민하고 있다.
그러나 메타데이터의 정보 관리 범위를 확장하더라도 과거의 수동 메타데이터 방식으로는 분산되고 점점 더 복잡해지고 거대해지는 데이터 환경하에서는 지속적이고 지능화 된 데이터 관리, 접근, 활용에 한계를 가질 수 밖에 없다.
데이터를 자산화하고, 민주화 된 활용이 제대로 이루어지기 위한 데이터 패브릭 체계로의 패러다임 전환을 위해서는 능동 메타데이터 구축이 필수적이다.
