

- 본 글은 데이터 민주화 1부는 한국데이터산업진흥원의 2021년도 데이터산업백서에 기고한 글입니다. -
많은 조직이 데이터라는 금광에 앉아 있지만 데이터의 잠재적 가치를 실현하기 위해 데이터를 분석할 효과적인 리소스가 부재한 상황이다. 이를 해결하기 위해서는 데이터를 필요로 하는 모든 개인에게 쉽게 접근하고 활용할 수 있는 체계를 제공하는 ‘소수 전문가에서 보통 사람으로의 데이터 활용 민주화’가 핵심적으로 필요하다.
1. 데이터 활용 민주화의 등장 배경
가. 데이터 주도 기업(Data Driven Enterprise)으로의 변화
오늘날 선두 기업은 점점 더 데이터 중심적으로 변모하고 있다. 조직은 모든 의사 결정과 행동에 데이터 파워를 갖기를 열망하며, 비즈니스 가설과 아이디어 검증에 사용하고자 한다.
그러나 데이터 보유 자체만으로는 비즈니스의 성공을 보장하기에 충분하지 않다. 데이터를 사용하여 비즈니스의 가시적 성과를 만들어내기 위해, 데이터를 기반으로 지속적인 지능화 사이클을 운영하는 데이터 주도 기업 체계를 갖추기 위해 노력하고 있다.
데이터 기반 지속적 지능화 사이클이란 ‘데이터를 바탕으로 한 의사결정 및 실행까지의 주기’가 ‘일회성이 아니라 지속적으로 빠르게 순환’되는 것을 의미한다. 지속적 지능화 사이클을 갖추기 위해서는 인사이트 생성 역량, 인사이트 채택 역량, 인사이트 적용 역량을 갖추고 상호 유기적으로 연계되어 작동해야 하지만, 대부분의 기업들은 이러한 역량을 갖추고 연결하는데 어려움을 겪고 있다.
![[ Figure 1. 데이터 기반 지속적 지능화 체계 ]](/news/photo/202201/301782_4848_621.png)
나. 지속적 지능화 장애 요인 해결을 위한 데이터 활용 민주화
대부분의 기업들은 데이터 수집-저장-처리-분석을 위한 리소스(애플리케이션, 인프라, 인력)를 소수의 데이터 전문가 팀에 의해 전담 운영하는 중앙집중적 방식을 취하고 있다. 즉, 조직을 위해 데이터를 적절하게 구성, 처리 및 해석하는 데 필요한 기술과 이해를 갖춘 소수의 데이터 분석 전문가에게 데이터 업무가 집중되어 왔다. 이는 여러 상황에서 데이터 기반 지능화의 장애요인으로 작용하고 있다.

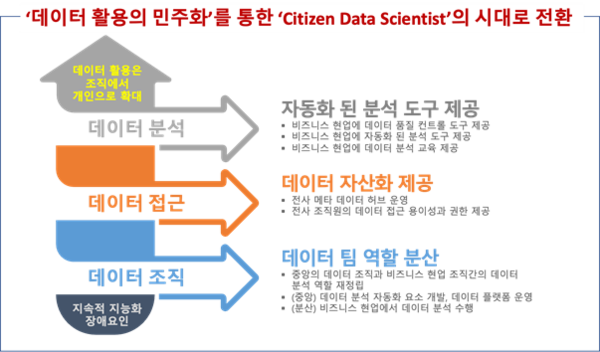
열거한 장애요인을 해결하기 위해서는 데이터 조직, 데이터 접근, 데이터 분석의 3가지 관점에서 접근이 필요하다. 대부분의 데이터에 대한 접근 권한과 도구는 중앙의 데이터팀에 있으며, 이는 데이터 접근과 활용의 사일로(Silo)를 만들어 내고 있다. 데이터 분석 모델을 생성하고 비즈니스 가치를 실현하는 속도는 고용한 데이터 엔지니어, 데이터 분석가의 수에 정비례한다. 이러한 데이터팀의 확장성 문제는 데이터 분석 비용을 크게 증가시킨다. 또한 데이터분석가에 대한 수요를 시장에서 대응하지 못하고 있다.
그러므로, 데이터에 대한 접근을 전사 조직원으로 확대하고 비즈니스 현업이 스스로 분석할 수 있는 자동화 된 분석도구 제공이 필요하다. 이를 통해 중앙에 집중된 데이터팀의 역할을 조직 전체로 확장하여 전 조직원 각자가 시티즌 데이터 사이언티스트(Citizen Data Scientist)로서 데이터를 활용하는 ‘데이터 활용의 민주화’가 요구되는 시점이다.
Gartner는 ‘2020년을 위한 10대 전략 기술 동향’ 중 하나로 ‘데이터 활용 민주화 시대’의 도래를 꼽았다. 데이터 활용 민주화는 데이터팀이나 IT 조직의 개입 없이 비즈니스 현업이 데이터에 언제든지 쉽게 접근・이해・활용할 수 있도록 하는 것으로 정의할 수 있다.
2. 데이터 활용 민주화 방안
가. 데이터팀의 역할 분산
가장 먼저, 기존의 중앙 집중적 데이터팀의 역할 분산이 필요하다.

1) 데이터 사이언티스트팀 역할 변화
중앙의 데이터 전담 조직은 데이터 분석 자동화를 위한 AI 모델을 지속적으로 연구・개발 하는 팀(데이터 사이언티스트)과 데이터 플랫폼을 관리하는 팀으로 역할 분담이 필요하다.
즉, 중앙의 데이터 분석팀의 역할은 기존의 비즈니스 분석 모델 개발(추천모델, 이탈모델, 고객 세그먼트 등)과 비즈니스 현업 부서의 다양한 분석 요구 대응 역할에서 ‘데이터 사이언스 과정 자동화‘가 가능한 AI 모델 개발에 주력하여, 비즈니스 현업 부서가 활용할 수 있도록 데이터를 제공하는 역할로 변화가 필요하다.
예를 들면 중앙의 데이터 분석팀에서는 이미지 인식에 대해 사전 훈련된 AI 모델, 텍스트 마이닝을 할 수 있는 NLP AI 모델, 데이터 전처리를 자동화 할 수 있는 모델 등을 수집, 연구, 개발하여 제공하고, 비즈니스 현업 부서에서는 이를 활용하여 비즈니스 분석 모델을 직접 개발하는 형태로의 역할 변화가 필요하다.
2) 데이터 플랫폼팀의 전문성 강화
데이터에 대한 수집, 저장, 처리, 제공, 분석, 배포를 위한 데이터 플랫폼 관리・운영 전담 조직의 역할 강화가 필요하다. 기하급수적으로 발생하는 내외부 데이터와 다양한 유형의 데이터스택(Data Stack)으로부터 데이터를 수집-처리-제공-분석-배포 하기 위해서는 과거의 정형 데이터・배치 중심 기술 인력에서 빅데이터・AI・실시간 기술을 이해하고, 이를 데이터 플랫폼에 지속적으로 반영하고 운영할 수 있는 전문성 있는 전담 인력 강화가 필요하다.
3) 비즈니스 현업 조직의 데이터 분석 직접 수행
비즈니스 현업 조직이 데이터 분석역할을 이관 받아 직접 수행하는 것이 필요하다. 앞서 언급했듯이, 중앙집중적 데이터 분석 팀은 시간적, 비용적, 효과적인 분석을 수행하는 데 한계를 보이고 있다.
이를 해결하기 위해서는 우선적으로는 데이터 엔지니어와 데이터 분석가를 각 팀에 분산시켜 현업의 분석업무를 현장에서 직접 지원하고, 이와 맞물려 데이터 자산화를 통한 현업의 데이터 접근 확대와 자동화된 데이터 도구의 제공, 교육을 통해 현업이 스스로 데이터를 분석할 수 있는 체계로 전환해 나가야 한다.
나. 데이터의 자산 활용체계 제공
데이터 분석 업무를 비즈니스 현업으로 확산시키기 위해서는 모든 조직원이 전사 메타데이터 허브를 통해 분산되어 있는 데이터에 접근하고, 이해하고, 활용할 수 있는 데이터 자산 활용 체계가 필요하다. 전사 메타데이터 허브는 데이터 카탈로그와 데이터 검색 엔진이 포함된 데이터 포탈의 형태로 구현되고 있다.
1) 확장된 데이터 카탈로그 접근 제공
데이터 카탈로그는 기존의 IT관리 중심의 기술 메타데이터 정보에서, 비즈니스 현업 조직이 이해하고 활용할 수 있는 비즈니스 메타데이터와 운영 메타데이터로 확장되어 제공되어야 한다.
또한 데이터 카탈로그는 데이터 자체에 대한 메타데이터 뿐만 아니라, 데이터가 어떻게 생성됐고, 어떤 과정을 거쳐 변경되었으며, 어디에 쓰이고 있는지에 대한 데이터 흐름 가시성 확보를 위한 데이터 계보(Data Lineage) 정보, 분석・활용을 위한 직관적인 도구와 사용자 인터페이스, 코드 조각 및 플러그인, 오픈소스 데이터 및 코드, 그리고 사전 훈련된 AI 모델 등이 포함되어 제공될 수 있도록 확장되고 있다. 즉, 메타 데이터 자체가 또 하나의 중요한 데이터셋 개념으로 운영되는 형태로 변화하고 있다.
![[ Figure 4. 데이터 카탈로그의 확장된 메타데이터 제공 범위 ]](/news/photo/202201/301782_4852_157.png)
2) 데이터 검색 엔진과 데이터 포탈 기능 강화
데이터 검색 엔진은 확장된 데이터 카탈로그를 기반으로 데이터 자체에 대한 검색 뿐만아니라, ‘데이터를 어떻게 사용하는지, 데이터는 어디에서 어떻게 변경되어 왔는지, 어떤 데이터가 가장 많이 활용되고 있는지, 해당 데이터의 오너십과 전문가는 누구인지, 해당 데이터는 누가 사용하고 있는지, 데이터 품질 수준은 어떤지’ 등을 제공할 수 있어야 한다.
이러한 확장된 범위의 데이터 카탈로그와 강화된 검색 엔진은 AirBnb의 Dataportal , Uber의 Databook , Netflix의 Metacat , Lyft의 Amundsen , Google의 Data Catalog , LinkedIn의 DataHub 등의 글로벌 선진 기업에서 데이터 포탈로 제공되고 있다.
![[ Figure 5. AirBnb의 Dataportal, Lyft의 Amundsen ]](/news/photo/202201/301782_4853_1634.png)
다. 자동화된 분석 도구 제공
비즈니스 현업 조직이 스스로 데이터를 분석하기 위해서는 데이터 품질 컨트롤 도구와 자동화된 분석 도구 제공이 필요하다.
1) 데이터 품질 컨트롤 도구 제공
각 조직에 걸쳐 분산되어 있는 데이터 테이블 생성으로 중앙의 데이터팀에서 데이터 품질을 컨트롤 하는데 한계를 보이고 있으며, 이는 데이터 품질 저하로 이어지고 있다. 이를 해결하기 위해서는 각 팀이 생성한 테이블에 대해 직접 품질 컨트롤을 수행할 수 있는 도구 제공이 필요하다.
2) AutoML(Automated Machine Learning) 도구 제공
기존에는 데이터 분석을 위해서 데이터 분석 전문가와 IT 개발자가 데이터 수집-저장-처리-분석- 적용에 이르는 각 단계별로 R과 Python 등의 데이터 처리・분석 언어를 이용하여 코딩을 수행해왔다. 이러한 전문성이 요구되는 데이터 분석업무를 프로그래밍 언어 지식과 통계지식이 취약한 비즈니스 현업 조직에게 교육으로 이양하기에는 어려움이 존재했다. 그러나 AutoML, Low Code・NoCode, Visual Analytics 등 여러 도구의 등장으로 데이터 분석업무의 자동화가 분석과정의 많은 부분을 비즈니스 현업 조직에 의해 직접 수행할 수 있는 환경으로 변화시키고 있다. 코딩 최소화 또는 코딩 없이 분석할 수 있는 도구를 통해 비즈니스 현업 조직의 직접 분석이 가능해지고 있다.
![[ Figure 6. 데이터 분석 과정 자동화 영역 ]](/news/photo/202201/301782_4854_1753.png)
대표적인 분석 자동화 솔루션 선두그룹으로는 DataRobot, H2O Driverless AI 등이 있다.
이외에도 프로그래밍 없이 어플리케이션을 개발・배포할 수 있는 Microsoft Power Apps, 시각화 분석을 통해 데이터 패턴을 쉽게 파악할 수 있는 Tableau, QlikView, Power BI 등도 비즈니스 조직의 데이터 분석 접근을 용이하게 하는 데이터 분석 자동화 솔루션이다.
3) 데이터 분석 교육 제공
비즈니스 현업의 데이터에 대한 이해도와 데이터 분석의 직접 수행 역량 강화, 조직 전반에 걸친 데이터 기반 의사결정 문화를 정착시키기 위해서는 데이터 교육을 통한 전 조직원의 데이터 리터러시 확보 또한 병행되어야 한다.
비즈니스 현업의 데이터 리터러시 확보를 위한 교육은 분석 언어 교육에 치중하기 보다는 조직의 문제를 해결할 수 있는 맞는 질문을 찾아내고(Problem Framing & Right Question), 필요한 데이터를 찾아내고(Data Curation), 다양하고 적합한 변수를 설계하고(Feature Engineering), 자동화 된 분석모델의 옵션을 조정하고 분석 결과의 의미를 제대로 해석할 수 있는 통계적 이해 역량 강화에 집중해야 한다.
![[ Figure 7. 비즈니스 현업의 데이터 리터러시를 위한 교육 영역 ]](/news/photo/202201/301782_4855_1851.png)
라. 데이터 거버넌스와 인공지능 공학 체계 운영
데이터 활용 민주화를 위해 필요한 데이터 분석의 역할 분산・데이터 자산화 관리와 운영・자동화된 분석 도구의 도입과 교육을 효과적으로 기획・실행・관리하기 위해서는 비즈니스 전략과 데이터 전략을 일치(Alignment)시키고, 데이터에 대한 역할과 책임을 관리하고, 데이터 플랫폼 인프라와 기술을 관리하고, 전사 데이터 리터러시 향상을 위한 교육을 기획하는 ‘데이터 거버넌스 체계’와 ‘인공지능 공학(AI Engineering: DataOps+ModelOps+DevOps) 체계’가 기반이 되어야 한다.
이상과 같이 데이터 분석・활용은 소수 데이터 전문가에서 전사의 조직원 개인으로 확대되는 데이터 활용의 민주화가 현재진행형으로 확산되고 있으며, 데이터 활용 민주화는 기업의 지속적 지능화를 작동시켜 데이터 드리븐 기업으로의 경쟁력을 강화하는 중요한 요소로 작용하고 있다.
